
Aquagena is a video game. Aquagena is also a planet, in a solar system of the Andromeda galaxy.
VR Drones Racing Beta subscription

Subscribe here to be part of the (Android) VR Drones Racing beta test, you’ll be notified by email as soon as the beta is available (in the comings weeks).
In a first time, these subscriptions will be limited to 100 seats.
Perspective – 1 : Projection
Rendering without computer: first video of a series about perspective.
Making of VR Drones Racing first track with LightWave
What you need to known About OpenGL ES(2) for Mobile Graphics
This is an article to explain quickly the differences between OpenGL for desktop GPU and OpenGL ES(2) for Mobile GPU. You need some OpenGL or 3D API background to understand what it’s about.

All Mobile devices today have something in common: a mobile Graphical Processor Unit (GPU) that can be programmed with OpenGL ES and OpenGL ES2. Every iPhone, iPads from apple include a PowerVR, Raspberry Pi embeds a “VideoCore IV”, Android models use all those, plus a wide range of other GPU like NVidia Tegra, adreno, snapdragon. A lot of models, but only 2 API to program them all at the lowest level:
OpenGL ES (quite the same as OpenGL1.x) and OpenGL ES2 (quite the same as.. OpenGL 3) … and yes, “ES” means a lot of differences…
Everything in this document is both from OpenGL documentation, specific GPU documentations, and my own experience testing with any kind of models.
No, the OpenGL ES driver will not be corrected by a system update in the future.
If you were used to hope for drivers updates on desktop to correct a bug or manage something differently, you have to know that GLES drivers are done once and for all for a given mobile GPU, quite often stands in ROMS and not in the system, and that basically the system (android,…) does not manage that part. and the GPU builder does not care because they just does no support after release.
Writing on FBO, and using glViewport() and glClear() differ *Totally*.
Framebuffer Objects (FBO) is the official way to create offscreen bitmaps and offscreen rendering, and you can link them to a texture Id.
The bad news is Mobile OGL Drivers only manage one FBO context at a time, and a whole FBO or screen are always internally “tile managed” by the driver, with possibly “implicit superscalar Buffers”, which means for you:
- glBindFramebuffer() must be followed by glViewport() and glClear(), if not it will crash on most Mobile GPU. You cannot “come back” to a FBO and continue drawing.
- glClear() will clear the whole FBO, not the rectangle given by glViewport(), unlike classic OGL. You absolutely can’t do one glViewport() on half the screen draw, then glViewport() the other half and draw again: impossible on all ES. Due to this, you should always give the whole rectangle to glViewport().
- (Due to 1 and 2) You must render your offscreens FBOs at the beginning of a frame, and then only begin to draw the screen. A nice idea is to have a list of off-screens to render with delegate functions/methods, so your program will automatically “sort” the order of your drawing needs for a given frame.
Texture Constants for glTexImage2D() are not the same in ES
There is a very wide list of texture pixel internal formats on classic desktop GL, that describes both the encoding and number of component: this is not re-used at all on OpenGLES(2), because you must have components and encoding separated. So glTexImage2D() have to be used differently. Read your GPU documentation about it.
To program in a way that is compatible on all OpenGL , both mobile and desktop, I have something like this in my headers: (note gl includes files also differs)
#ifdef USE_GLES_TEXTURES
// for OpenGL ES 1/2: textures are not set
// use 16 hight bits to set the format enum(GL_UNSIGNED_BYTE,GL_FLOAT)
// the low 16 bits for the number of component enum:
// watch out, glTexImage2D() isn't used the same way either
typedef enum {
epf_Byte_R=GL_LUMINANCE|(GL_UNSIGNED_BYTE<<16),
epf_Byte_RG=GL_LUMINANCE_ALPHA|(GL_UNSIGNED_BYTE<<16),
epf_Byte_RGB=GL_RGB|(GL_UNSIGNED_BYTE<<16),
epf_Byte_RGBA=GL_RGBA|(GL_UNSIGNED_BYTE<<16),
epf_Float32_R=GL_LUMINANCE|(GL_FLOAT<<16),
epf_Float32_RG=GL_LUMINANCE_ALPHA|(GL_FLOAT<<16),
epf_Float32_RGB=GL_RGB|(GL_FLOAT<<16),
epf_Float32_RGBA=GL_RGBA|(GL_FLOAT<<16),
epf_Float16_R=GL_LUMINANCE|(GL_HALF_FLOAT_OES<<16),
epf_Float16_RG=GL_LUMINANCE_ALPHA|(GL_HALF_FLOAT_OES<<16),
epf_Float16_RGB=GL_RGB|(GL_HALF_FLOAT_OES<<16),
epf_Float16_RGBA=GL_RGBA|(GL_HALF_FLOAT_OES<<16),
} ePixelFormat;
#else
// Classic desktop OpenGL stuff:
typedef enum {
epf_Byte_R=GL_LUMINANCE8,
epf_Byte_RG=GL_LUMINANCE8_ALPHA8,
epf_Byte_RGB=GL_RGB8,
epf_Byte_RGBA=GL_RGBA8, .
epf_Float32_R=GL_LUMINANCE32F_ARB,
epf_Float32_RG=GL_LUMINANCE_ALPHA32F_ARB,
epf_Float32_RGB=GL_RGB32F_ARB,
epf_Float32_RGBA=GL_RGBA32F_ARB,
epf_Float16_R=GL_LUMINANCE16F_ARB,
epf_Float16_RG=GL_LUMINANCE_ALPHA16F_ARB,
epf_Float16_RGB=GL_RGB16F_ARB,
epf_Float16_RGBA=GL_RGBA16F_ARB,
} ePixelFormat;
#endif
and in my inits (for FBO actually):
#ifdef USE_GLES_TEXTURES // OpenGL ES 1 or 2: unsigned int components =(unsigned int)( pixelFormat & 0x0000ffff); unsigned int format =(unsigned int) ((pixelFormat>>16)& 0x0000ffff); glTexImage2D(GL_TEXTURE_2D, ii, components , pixelWidth, pixelHeight, 0, components, format, NULL); #else // OpenGL 1,2 not ES glTexImage2D(GL_TEXTURE_2D, ii, pixelFormat , pixelWidth, pixelHeight, 0, GL_RGBA, GL_UNSIGNED_BYTE, NULL); #endif
…Then by using the ePixelFormat enum in my code, I can stay compatible on desktop and mobile.
Note something special about texture size: Textures and FBO can be any pixel size on OpenGL ES and ES2, with all implementations: no need to test for extensions, NPOT (Non power Of Two size) is mandatory on ES (and for ES2, GL’s extension list will not display NPOT just because it doesn’t have to, but it’s here.)
Last word about texture formats: NVidia Tegra allows to have internal float16 RGBA textures (not float32 or else) and to write them as float16 with a FBO and a pixel shader, so you can do some nice “General purpose GPU” (GPGPU) tricks on it. As far as I know, a lot of other GPU declare float texture format extensions but it’s only the loading format. they all are restricted to 8 bit FBO internally. (tested last time in 2014)
With OpenGLES2 (like OpenGL 3 desktop) No more glColor function, no more matrix management,…
For both Mobile ES and desktop OpenGL, a “2” or greater version number means it is a Shader-based architecture that needs a vertex Shader and pixel Shader to draw something.
If you want to use the real power of your GPU, you have to use shaders.
And if you want shaders on mobile, you’ll have more code to do than with OpenGL 1.
Basically in OpenGL ES2 and OpenGL3, every GL functions that could be also done with shaders using using “attributes” and “uniform”, were removed.
So every glMatrix functions were removed, you have to declare your own uniform matrix and apply them your own way in the vertex shader. It implies you have your own translate, rotate, multiply, etc matrix implementations… extra SDK often offer their (NVIDIA Tegra SDK, any open source engine,…) I did my own. It’s always useful to patch 4×4 float matrices in a way or another.
OpenGL ES2 GLSL Shaders are a bit differents compared to classic GLSL.
First some simple rules:
a. Your Mobile GPU is far more powerfull than the ARM FPU: It’s always better to have computation in your Vertex Shader rather than in the CPU Float code. Think about it twice, you can have “quite big vertex shaders”, there is no problems.
b. You can’t read textures in vertex shader under OpenGL ES 2. Arggg I hate that. It actually would have been the coolest thing ever, some (rare) mobile GPU and drivers actually does it, but you want to be compatible.
Then the only real serious thing to know about GLSL for mobile:
You must start every Shader with one of these lines:
precision lowp float; precision mediump float; precision highp float;
… This precision thing only exists for ES shader and is mandatory.
It allows to choose if the GPU would work with 8b float16 or float32
It is meant to be powerful, because lowp would be enough for copying 8bit textures and highp would allow more nice rendering.
This is the default main precision of your shader, but you can then declare for each variable any lowp, mediump or highp precision. Theorically, it will finetune the compilation of the shader. But complex shading will need highp to really work. Some glitches are sometimes caused by mediump.
The Dreaded Android Context loss and other Video Memory management issues…
Even if modern Mobile hardware got huge memories, Androids and other systems are still widely ” One App Focused at a time” based. Before Android 3, Every OpenGL app had to completely free all textures, FBO and VBO each times the system was paused, and you had to re-init all of these when the App restart. Even the screen-rotation-with-sensor implied to do all of that, and for a game with many textures and FBO, it was a hell, not mentioning you are meant to manage GL in a special thread… that the main thread will actually kill your context *before* sending the message on the other thread. Android “Activity” class has special messages about it. Hopefully, Android 3 introduced setPreserveEGLContextOnPause() which will just prevent that behavior… in most cases. Because yes: you still have to manage the “destroy and recreate the GL video memory, but you can keep the rest” thing.
and you know what ? it’s great to do that. I have 2 level of creation/ destruction messages in my whole engines , one for video memory and the other for CPU memory. As I can compile for destop and mobile GL, it also resolves the nasty windows and OSX bug in SDL that destroy the context when you change the size of the screen.
That’s all, have a nice code.
Introducing the VR Drones Racing project
You may have noticed my interest in VR headsets and race tracks’ modeling, well i think it’s time to introduce you the project i’ve been working on for several months now : VR Drones Racing

You guessed it, this project is about a drone racing game for virtual reality.
It’s intended to run on Android and iOS, maybe on oculus later, but this is not my first target. I really think that VR will be a mobile thing.
My current prototype allows me to play against 5 oponnents on a complete track and is running quite smoothly on an old Galaxy Nexus.
I still have to rework the oponnents’ AI, and produce most of the 2D and 3D graphical assets.
I will publish posts as much as possible during the development.
Math Touch Book released
Our dear Krabob have just released Math Touch Book on iOS and Android.
Get it now !
The app was not found in the store. 🙁 #wpappbox
Links: → Visit Store → Search Google
Links: → Visit Store → Search Google
The app was not found in the store. 🙁 #wpappbox
Links: → Visit Store → Search Google
Links: → Visit Store → Search Google
Fl Studio to Bitwig – How to Convert loop audio and midi
This video shows how to convert audio and midi loops from FL Studio to Bitwig.
This is also working to export to other music softwares.
The sample BPM (beat per minute) will be embedded in the rendered file.
We can also use this basic method to record all the tracks in one row, to make loops or final mastering.
Mastering multicore: Parallelizing any algorithms… and how my resource library helps
As in any big project, I use several program libraries for Math Touch Book.
I actually made a brand new Graph Theory API for it, to fit my needs. But I use another one I did between 2006 and 2009, to manage what is called application resources. This was a very interesting management library called Veda. In the case of Math Touch Book, I just re-used it to manage icons, screens, and messaging between objects. Thanks to Veda, If I need one more image for a button, I only add the image once and I have it both in the Android and iOS Apps, and for any future implementation. If I want to get rid of unused images or doubles, it is also automatized for all app versions.

Veda is like a C++ patch where you add some declaration to the class you want to be managed. Then you have special serializable members (serializable means loadable/ savable/clonable). with basic data types of any kind, and one of the magic was special intelligent pointers that allowed to view your whole data as a graph with object links and dependencies. It was first made to experiment with “naked object” design pattern, which is about having interfaces to edit objects by just declaring objects, with no additional code. I also had some experiments with Java serialization, and my old xml based Amiga engine “Karate” was lacking automatic interfaces.
For your information, it is opensource and available here (and you even have Sega Dreamcast demos done with it !):
Veda source and binaries… mostly for windows xp
and Tons of Veda docs were “doxygened” here.
As your whole objects could be managed as a graph, It was made possible to have incremental step-by step initializations for it: when You ask the construction phase of an object, It could need another linked object to be created first, and this second object could also be bound to a third ante-previously initialized object.
At the time veda was made, it had implementation for a 3D engine (that was drawn through an abstract engine, with 5 or 6 different implementations !) . In that case, I had a veda Script classes, which needed some 3D world, which needed 3d objects and cameras, which needed another 3D objects and 3D textures, which needed images of any kind.
But anything in computer science could be Veda-managed, not only 3D engines.
All those objects were linked with intelligent pointers, and an algorithm was able to list all the objects in a leaf-to-root order, to assume you created the leaf objects and then only the dependent ones. A leaf object could be pointed many times, and any object could point another (exception was: you could not “ring” pointers), so it was really a Graph, not a tree.
So incremental initialisations were automatized, Interfaces were automatized, links and data were dynamics, whatever may be the size of the whole graph . My previous space video game “Earths of alioth” also used Veda to manage resources, and its nice progress bar at start, is done thanks to Veda.
At the time, I couldn’t cease to discover new advantages of Graph-theory managed resources in veda, that explains the never ending list of its features.
One of the biggest ideas came with the advent of multi core CPUs...
Since the mid-2000’s, we have efficient multi-core CPU, which means 2 or more programs can run at the same time, not only because of Preemption (which means: multi-tasking with one CPU), but because you really have multiple CPU working, which was impossible before the 2000’s, because of data cache and hardware memory issues: 2 CPU accessing the same memory would trash the memory.

But then, the problem was to create multi-core programming. in most cases, programmers didn’t change their habits: you use multi-core with long-known threads, and usually, a thread works on its own job, with its own data. For example, a thread would mix sounds alone, when a main thread would do something else.
In the case of very large computation to be performed using the same data, it is often hard to split an algorithm to make the CPU work in parallel. Because you have to be sure the data you read is coherent with what the other CPU are doing in the same time.
Basically, such an API like Veda could do that: for example, you can delegate the inits of whole branches of objects to other CPU threads when you know they are on a “separated branch”, and recover those objects to another thread when initialized.
To make it short and generalize it, knowing the graph of dependencies between objects, makes it possible to automatise the way multiple CPU can share their work with it: it’s just about some lines of Graph-theory algorithms to do that.
Thanks for your attention and have a nice day !
A Simple yet Powerful Artificial Intelligence Algorithm.
One of the Key Word about Interfaces today is Responsive Design: For a Mobile App, interfaces not only have to be the simplest possible, they have to be clear, and they have to propose only awaited functionalities that users will understand: they had to be adaptative.
So not surprisingly, Math Touch Book displays nothing else than what you wrote on the screen. Then touching a Math expression unfolds a Menu that proposes a short list of features according to that expression.

Adaptative Menus are not new, but here, the program must “think” to guess the list of functionalities, operations, modifiers: Expressions can be developed or not, Simplified or not, resolved or not. And notice, some of those features can take multiple passes, like Equation resolutions.
It might surprise you, but a bit of Artificial Intelligence (AI) intervenes at this level: The same basic AI algorithm is used, both to select the menu entries and to resolve equations.
With the advent of multi-threaded mobile CPU and GPUs this last decade, Robotics and Artificial intelligence are subject to permanent breakthrough. On the software side the AI subject becomes bigger every day. But large industrial AI programs for robots, that have to compute an impressive sum of data, and more little algorithms managing equations (like MathTouch Book does) have things in common: they both manage their objects using Graph Theory, and they both create and test algorithms before applying them for real.
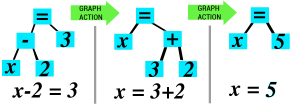
Let’s have a look at what Math Touch Book does when it resolves an equation:
First, Equations are defined by Graph Trees, where the root element is an equal sign.
Elements in a tree are all attached to another. That’s what Graph Theory is about and we, computer scientists, usually think it’s a nice way to manage data.
A good Graph theory framework should also have methods for cloning graphs, detaching branches of the tree, re-attach them elsewhere, and the ability to use one or another element allocators, amongst other things.
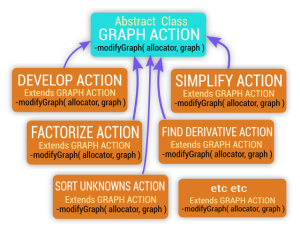
Then we have some bricks here, that represents schematically classes available in the program, it’s a “Object Oriented” concept. This scheme tells us each of these classes are “GraphActions”, and each is able to modify a graph in their own way. They are available to be used by the Artificial Intelligence.
So now that we know the shape of the data, the tools to modify it, we want the program to find itself a way to resolve the equation. How ?
An equation resolution algorithm can be expressed as a list of “GraphActions”. But what GraphActions to use, in what order ?
And what happens if the program find a wrong algorithm ? the graph would be destroyed !
No, because we can clone the graph and test modifications on the clone.
we can also simply look at the shape of a graph, and decide to modify it in a way or another according to its shape. (You now understand the usefulness of having clone functions and special allocators in your graph framework.)
Written in pseudo-code, you can find a resolution algorithm like this:
class changeThisShapeAction extends GraphAction
class changeTHATShapeAction extends GraphAction
...
get_Action_List_For_Resolution( listOfActions , equationGraph )
{
tempGraphAllocator // init an allocator to experiement
// create a temporary clone to experiment
cloneOfEquation = equationGraph.clone(tempGraphAllocator)
// this loop search a shape that can be resolved
while( cloneOfEquation has no resolvable shape )
{
if(cloneOfEquation has "this" shape)
{
didSomething = changeThisShapeAction.
modifyGraph(tempGraphAllocator,cloneOfEquation);
if(didSomething) listOfActions.add(changeThisShapeAction)
}
if(cloneOfEquation has THAT shape)
{
didSomething = changeTHATShapeAction.
modifyGraph(tempGraphAllocator,cloneOfEquation);
if(didSomething) listOfActions.add(changeTHATShapeAction)
}
(... here are a lots of modifier actions to test accordingly)
} // end of loop
// here equation could be resolvable or not :
if(cloneOfEquation first degree) listOfActions.add(finaliseFirstDegree)
if(cloneOfEquation is quadratic) listOfActions.add(finaliseQuadratic)
if(cloneOfEquation not resolvable) listOfActions.add(finaliseNoSolution)
// the magic here, is we just cancel everything done on the tempGraph...
tempGraphAllocator.free()
// We return the exact list of modifiers that finds the solution.
return listOfActions
}
Acting innocently, with just one accumulator list, a loop and an object oriented set of classes, we have here an algorithm that … creates an algorithm. and it works !
The human brain actually does more or less this “imagine what is the most interesting thing to do, and then do it” game. The temporary allocated memory can be seen as a short-lived “imagination”. Obviously the real code is a little bigger, but the main idea is here.
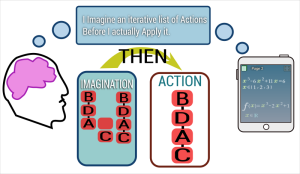
To me, the greatest of all things is that, at this level, the algorithm is found, it is available for use, but you can or cannot use it inside the application; it’s up to the user, he may use another modifier, and in some way this “search what to do” Artificial Intelligence algorithm can also be seen as a recursive extension of the Natural Intelligence of the user, that decides, the same way, to use or not a feature. So it may demonstrates that Artificial intelligence and Natural Intelligence can cooperate.
In this perspective, one already can speak of Human Bananas.
