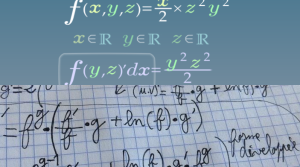This is an article to explain quickly the differences between OpenGL for desktop GPU and OpenGL ES(2) for Mobile GPU. You need some OpenGL or 3D API background to understand what it’s about.

All Mobile devices today have something in common: a mobile Graphical Processor Unit (GPU) that can be programmed with OpenGL ES and OpenGL ES2. Every iPhone, iPads from apple include a PowerVR, Raspberry Pi embeds a “VideoCore IV”, Android models use all those, plus a wide range of other GPU like NVidia Tegra, adreno, snapdragon. A lot of models, but only 2 API to program them all at the lowest level:
OpenGL ES (quite the same as OpenGL1.x) and OpenGL ES2 (quite the same as.. OpenGL 3) … and yes, “ES” means a lot of differences…
Everything in this document is both from OpenGL documentation, specific GPU documentations, and my own experience testing with any kind of models.
No, the OpenGL ES driver will not be corrected by a system update in the future.
If you were used to hope for drivers updates on desktop to correct a bug or manage something differently, you have to know that GLES drivers are done once and for all for a given mobile GPU, quite often stands in ROMS and not in the system, and that basically the system (android,…) does not manage that part. and the GPU builder does not care because they just does no support after release.
Writing on FBO, and using glViewport() and glClear() differ *Totally*.
Framebuffer Objects (FBO) is the official way to create offscreen bitmaps and offscreen rendering, and you can link them to a texture Id.
The bad news is Mobile OGL Drivers only manage one FBO context at a time, and a whole FBO or screen are always internally “tile managed” by the driver, with possibly “implicit superscalar Buffers”, which means for you:
- glBindFramebuffer() must be followed by glViewport() and glClear(), if not it will crash on most Mobile GPU. You cannot “come back” to a FBO and continue drawing.
- glClear() will clear the whole FBO, not the rectangle given by glViewport(), unlike classic OGL. You absolutely can’t do one glViewport() on half the screen draw, then glViewport() the other half and draw again: impossible on all ES. Due to this, you should always give the whole rectangle to glViewport().
- (Due to 1 and 2) You must render your offscreens FBOs at the beginning of a frame, and then only begin to draw the screen. A nice idea is to have a list of off-screens to render with delegate functions/methods, so your program will automatically “sort” the order of your drawing needs for a given frame.
Texture Constants for glTexImage2D() are not the same in ES
There is a very wide list of texture pixel internal formats on classic desktop GL, that describes both the encoding and number of component: this is not re-used at all on OpenGLES(2), because you must have components and encoding separated. So glTexImage2D() have to be used differently. Read your GPU documentation about it.
To program in a way that is compatible on all OpenGL , both mobile and desktop, I have something like this in my headers: (note gl includes files also differs)
#ifdef USE_GLES_TEXTURES
// for OpenGL ES 1/2: textures are not set
// use 16 hight bits to set the format enum(GL_UNSIGNED_BYTE,GL_FLOAT)
// the low 16 bits for the number of component enum:
// watch out, glTexImage2D() isn't used the same way either
typedef enum {
epf_Byte_R=GL_LUMINANCE|(GL_UNSIGNED_BYTE<<16),
epf_Byte_RG=GL_LUMINANCE_ALPHA|(GL_UNSIGNED_BYTE<<16),
epf_Byte_RGB=GL_RGB|(GL_UNSIGNED_BYTE<<16),
epf_Byte_RGBA=GL_RGBA|(GL_UNSIGNED_BYTE<<16),
epf_Float32_R=GL_LUMINANCE|(GL_FLOAT<<16),
epf_Float32_RG=GL_LUMINANCE_ALPHA|(GL_FLOAT<<16),
epf_Float32_RGB=GL_RGB|(GL_FLOAT<<16),
epf_Float32_RGBA=GL_RGBA|(GL_FLOAT<<16),
epf_Float16_R=GL_LUMINANCE|(GL_HALF_FLOAT_OES<<16),
epf_Float16_RG=GL_LUMINANCE_ALPHA|(GL_HALF_FLOAT_OES<<16),
epf_Float16_RGB=GL_RGB|(GL_HALF_FLOAT_OES<<16),
epf_Float16_RGBA=GL_RGBA|(GL_HALF_FLOAT_OES<<16),
} ePixelFormat;
#else
// Classic desktop OpenGL stuff:
typedef enum {
epf_Byte_R=GL_LUMINANCE8,
epf_Byte_RG=GL_LUMINANCE8_ALPHA8,
epf_Byte_RGB=GL_RGB8,
epf_Byte_RGBA=GL_RGBA8, .
epf_Float32_R=GL_LUMINANCE32F_ARB,
epf_Float32_RG=GL_LUMINANCE_ALPHA32F_ARB,
epf_Float32_RGB=GL_RGB32F_ARB,
epf_Float32_RGBA=GL_RGBA32F_ARB,
epf_Float16_R=GL_LUMINANCE16F_ARB,
epf_Float16_RG=GL_LUMINANCE_ALPHA16F_ARB,
epf_Float16_RGB=GL_RGB16F_ARB,
epf_Float16_RGBA=GL_RGBA16F_ARB,
} ePixelFormat;
#endif
and in my inits (for FBO actually):
#ifdef USE_GLES_TEXTURES // OpenGL ES 1 or 2: unsigned int components =(unsigned int)( pixelFormat & 0x0000ffff); unsigned int format =(unsigned int) ((pixelFormat>>16)& 0x0000ffff); glTexImage2D(GL_TEXTURE_2D, ii, components , pixelWidth, pixelHeight, 0, components, format, NULL); #else // OpenGL 1,2 not ES glTexImage2D(GL_TEXTURE_2D, ii, pixelFormat , pixelWidth, pixelHeight, 0, GL_RGBA, GL_UNSIGNED_BYTE, NULL); #endif
…Then by using the ePixelFormat enum in my code, I can stay compatible on desktop and mobile.
Note something special about texture size: Textures and FBO can be any pixel size on OpenGL ES and ES2, with all implementations: no need to test for extensions, NPOT (Non power Of Two size) is mandatory on ES (and for ES2, GL’s extension list will not display NPOT just because it doesn’t have to, but it’s here.)
Last word about texture formats: NVidia Tegra allows to have internal float16 RGBA textures (not float32 or else) and to write them as float16 with a FBO and a pixel shader, so you can do some nice “General purpose GPU” (GPGPU) tricks on it. As far as I know, a lot of other GPU declare float texture format extensions but it’s only the loading format. they all are restricted to 8 bit FBO internally. (tested last time in 2014)
With OpenGLES2 (like OpenGL 3 desktop) No more glColor function, no more matrix management,…
For both Mobile ES and desktop OpenGL, a “2” or greater version number means it is a Shader-based architecture that needs a vertex Shader and pixel Shader to draw something.
If you want to use the real power of your GPU, you have to use shaders.
And if you want shaders on mobile, you’ll have more code to do than with OpenGL 1.
Basically in OpenGL ES2 and OpenGL3, every GL functions that could be also done with shaders using using “attributes” and “uniform”, were removed.
So every glMatrix functions were removed, you have to declare your own uniform matrix and apply them your own way in the vertex shader. It implies you have your own translate, rotate, multiply, etc matrix implementations… extra SDK often offer their (NVIDIA Tegra SDK, any open source engine,…) I did my own. It’s always useful to patch 4×4 float matrices in a way or another.
OpenGL ES2 GLSL Shaders are a bit differents compared to classic GLSL.
First some simple rules:
a. Your Mobile GPU is far more powerfull than the ARM FPU: It’s always better to have computation in your Vertex Shader rather than in the CPU Float code. Think about it twice, you can have “quite big vertex shaders”, there is no problems.
b. You can’t read textures in vertex shader under OpenGL ES 2. Arggg I hate that. It actually would have been the coolest thing ever, some (rare) mobile GPU and drivers actually does it, but you want to be compatible.
Then the only real serious thing to know about GLSL for mobile:
You must start every Shader with one of these lines:
precision lowp float; precision mediump float; precision highp float;
… This precision thing only exists for ES shader and is mandatory.
It allows to choose if the GPU would work with 8b float16 or float32
It is meant to be powerful, because lowp would be enough for copying 8bit textures and highp would allow more nice rendering.
This is the default main precision of your shader, but you can then declare for each variable any lowp, mediump or highp precision. Theorically, it will finetune the compilation of the shader. But complex shading will need highp to really work. Some glitches are sometimes caused by mediump.
The Dreaded Android Context loss and other Video Memory management issues…
Even if modern Mobile hardware got huge memories, Androids and other systems are still widely ” One App Focused at a time” based. Before Android 3, Every OpenGL app had to completely free all textures, FBO and VBO each times the system was paused, and you had to re-init all of these when the App restart. Even the screen-rotation-with-sensor implied to do all of that, and for a game with many textures and FBO, it was a hell, not mentioning you are meant to manage GL in a special thread… that the main thread will actually kill your context *before* sending the message on the other thread. Android “Activity” class has special messages about it. Hopefully, Android 3 introduced setPreserveEGLContextOnPause() which will just prevent that behavior… in most cases. Because yes: you still have to manage the “destroy and recreate the GL video memory, but you can keep the rest” thing.
and you know what ? it’s great to do that. I have 2 level of creation/ destruction messages in my whole engines , one for video memory and the other for CPU memory. As I can compile for destop and mobile GL, it also resolves the nasty windows and OSX bug in SDL that destroy the context when you change the size of the screen.
That’s all, have a nice code.




 Early before 1990, Hackers started to explore experimental real-time effects on computers, with graphics and musics. This movement, rapidly spread, involved a lot of research, both technical and artistic.
Early before 1990, Hackers started to explore experimental real-time effects on computers, with graphics and musics. This movement, rapidly spread, involved a lot of research, both technical and artistic.
 e montage techniques, experimentations with sound and image symbiosis, exploded during the nineties in these movies, like nowhere else.
e montage techniques, experimentations with sound and image symbiosis, exploded during the nineties in these movies, like nowhere else.
 You could read the word “Multimedia” during years on ads and brochure, until the mid 2000’s: the fashion more or less lasted a decade. At that time, kids were already raised with internet, and the adults had more frequently computer knowledge and computer culture, not mentioning all media becoming digital.
You could read the word “Multimedia” during years on ads and brochure, until the mid 2000’s: the fashion more or less lasted a decade. At that time, kids were already raised with internet, and the adults had more frequently computer knowledge and computer culture, not mentioning all media becoming digital.
 e analysis about culture and state of the Art as could do an independent underground demomaker, and even more, using the same words: Post Media. Signs of the time: pixel Artists like eBoy are nowadays praised in galleries. Displaying a background of underground computer geek and experimenter does not scare anymore, quite the reverse, it opens doors.
e analysis about culture and state of the Art as could do an independent underground demomaker, and even more, using the same words: Post Media. Signs of the time: pixel Artists like eBoy are nowadays praised in galleries. Displaying a background of underground computer geek and experimenter does not scare anymore, quite the reverse, it opens doors.